
Bacula
Bacula is a backup system that Wikimedia has been using since 2013.
Objective
To have some in house and reliable system to store backed up versions of selected data (that is, NOT everything) for a period of time that is in accordance with our privacy policy. The data should be stored in a secure way to avoid leaking information via e.g. hard disks
History
- Main article: Bacula/history
The switch to Bacula bypassed some of the problems with previous Amanda setup, including disk space problems on its host (tridge). In 2013-06-10 ops meeting it was proposed that the NFS/iSCSI shares on the Netapps could be used to solve the problem stated above but it was quickly pointed out that both NFS and iSCSI communications are unencrypted. At the same time there are possible concerns with the state of the backups being unencrypted on the end disks as well. We could use encrypting file systems either at block level (iSCSI) or filesystem level (eCryptFS) to solve the problems above. However that would cause problems like encryption key handling, leak of information (filesystem names in ecryptfs case) and the possible loss of all encrypted data due to the SPOF that the backup server is all of which given the specific problem in hand could be avoided. Given all that it was proposed that we use bacula who has inherent encryption both for communications and storage, no information leaking and the capability for a master key allowing decryption of encrypted data.
General bacula information
The stuff below is not WMF specific.
Bacula Architecture
The following png probably illustrates the bacula architecture better than words
https://www.bacula.org/9.2.x-manuals/en/images/bacula-applications.png
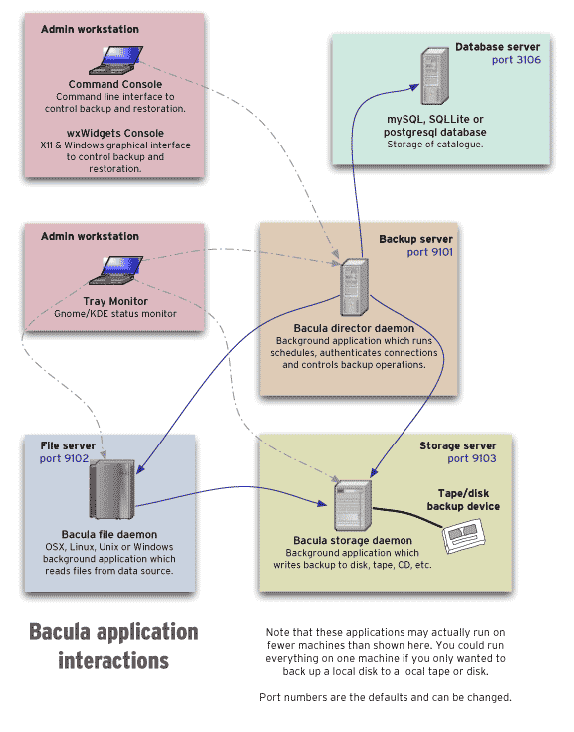{kind=link}
A couple of notes:
- There is one Director Daemon only.
- There may be multiple Storage Daemons (or SD for short) (for example one per datacenter)
- There is going to be one File Daemon (or FD for short) per machine to be backed-up.
- All communications (indicated by arrows in the PNG) can be encrypted.
- There are passwords that authenticate each party to all the others. TLS/SSL can be used in addition.
- The data store can be Tapes, Files, DVDs, Diskettes. All are called Volumes. The specifics of each medium is abstracted by bacula in day to day operations.
- The SQL server stores the catalog. It is used as the fist place where information should be sought when needed. However it is not the primary source of information. This resides depending on case in the Volumes, configuration files and bootstrap files [1].
Some more information on the various concepts of bacula follows
Jobs
Jobs are the essential unit of activity in Bacula. Whatever bacula does is a job. Whether it backups, restores, verifies a backup or just moves things around in its volumes/pools it is defined as a Job. Jobs are quite flexible allowing to run arbitrary commands before and after a backup as well as supporting file level de-duplication, verification of backups, multiple storage destinations and pools
Jobdefs
Since jobs have way too many attributes that can be defined, jodefs (short for job defaults) work as a way of storing all the standard attributes that don't change between jobs and that way keep job definitions short. Think of it as an abstract definition that is inherited by the more concrete definitions of jobs.
Levels
Backup levels are:
- Full (backup everything specified)
- Differential (backup the changes from the previous Full)
- Incremental (backup the changes from the previous Full, Differential or Incremental)
Schedules
A schedule defines when a job will take place. It supports various formats for defining that "when". This is heavily used for definining the levels easily and in an understandable way. For example
Schedule {
name="mysched"
Run= Level=Full 1st Sat at 06:00
Run= Level=Differential 3rd Sat at 06:00
Run= Level=Incremental sun-fri at 07:00
}
Filesets
These define what should be backed up and what not. They work by including a directory (or File) and recursing under that backing up everything. The possibility of exclusions does exist, either by filtering out by name or wildcard, regex etc. Generally filesets do not span file-systems in order to avoid backing up by default file-systems like sysfs or procfs but this can be turned off (provided you know what you are doing). Sparse files are supported, so are whole block devices.
Volumes
Volumes is what the data get's stored in. Mostly an abstraction layer for hiding device specific behavior from the other components of bacula. Examples of volumes are:
- tapes
- files
- DVDs
- diskettes (party like it's 1995!!!)
- FIFOs.
Volumes have unique IDs called labels. A volume can be labelled either manually or preferably automatically either through an autochanger (a component of a hardware Tape library) or internally by bacula.
Pools
Pools are just aggregates of volumes. They exist mostly so that jobs can span more than one volume (very useful feature). They are the destination point for backups hiding the volume specifics from the rest of the configuration. Its is a requirement that all volumes in a Pool are of the same type (e.g. DVDs). A job can not span >1 Pool.
Encryption
There are a number of communication channels in a standard bacula setup as shown in architecture. All of them can be configured to be encrypted independently of the others. Please do note that we are talking about communications here and not storage so we are talking about encryption of the TCP connection (yes that means SSL/TLS). These are:
- Control channels. All paths in the architecture diagram starting starting from the Director or going to the Director are control channels. The main reason these should be encrypted is to avoid leak of the username/password used by the director to authenticate itself to the other daemons, since if these leak, impersonation of the director becomes possible (and relatively easy). Also control channels carry client's (backed-up server) file metadata and that should be protected as well.
- Data channels. Paths for the communication between the Storage Daemon and the File Daemon. These contain the actual data. No reason explaining why they should be encrypted (there is however a reasoning behind not encrypting this, see below).
Note that the above is all about the network part of things. However encryption at rest might also be a requirement. The File Daemon can be configured to send their data encrypted to the Storage Daemon. In that case the actual data never leaves the client unencrypted and is stored encrypted at the end medium (Tape, Disk, DVD or diskette). In this case the data path could be already considered encrypted so another layer of encryption at the communications layer is quite possible unnecessary (TODO: confirm this). The data is encrypted using the private key of an SSL certificate and can only be decrypted with that key or a Master key.
SPOFs
The following is a documentation of the various places where problems might occur
- The director. Indeed a SPOF. No multiple directors are allowed at this point and the hostname is the username in control channels. Failure of the director will cause all backups and restore to not be possible. Reinstalling a new director is however relatively easy.
- The catalog. A standard MySQL server. We could have a hot-standby slave to avoid a SPOF. Backups running during failover will fail.
- The storage daemon. Multiple storage daemons can exist albeit they do different jobs. The failure of a storage daemon will lead to all backups and restores associated with that daemon to fail. The same problem with the director regarding the hostname/password scheme exists. Reinstalling a new storage is however relatively easy.
- The data store. NAS, Tape Library, DVD/CD burner etc. A major SPOF from a hardware perspective. Bacula can not do much about it, aside from having the backups mirrored in >1 locations.
WMF specifics
Architecture
A service in EQIAD is used as a director and a storage daemon. Another server in codfw is used as a storage daemon for redundancy purposes. Additional storage daemons also exist (see below). The data is stored encrypted with the file deamon's Puppet certificate key. Only the file daemon and the puppet CA master key can decrypt the data. The clients use encrypted control channels for communication with the director daemon and the storage daemon.
Off-site backups
The codfw storage daemon is used as a mirror.
What to backup
This is on a case by case basis, configured into puppet.
DB Backups
While before it used to be integrated with bacula, this created issues on performance and concurrency when the sizes grew. Since 2018, a separate system is used that still eventually uses bacula for long term backups, but otherwise is separate for backup generation, provisioning and snapshoting: MariaDB/Backups.
The old bacula integration is still available if needed, and at least analytics is using it for internal dbs.
Retention
Most pools have a retention of 3 months, so they are regularly scheduled and refreshed, and there are several copies to recover. Certain pools, however, setup for archival purposes, or of backups of read-only data, have indefinite retention, marked as "5 years", but because they are static, they won't be ever deleted unless they receive new activity.
Configured Pools
The following "Pools" are configured on the director, and its respective devices on the storage daemons:
Default: small pool needed internally by baculaProduction: stored locally to the director daemon (backup1001), in its first disk array, it stores most of the configured jobs (filesystem backups not related to databases)Archive: long-term archival of some things that we may want to retain for longer, only for internal projects that, normally, have been deleted from production. For example, they contain the old bacula database for the previous setup, now deleted from production. Unlike most pools, this has a retention of 5 years (but because it is static, it may take more than that to be deleted). It lives in backup1001.Offsite: it has not backups configured, but internally, it has configured a job to copy backups from the production pool and send it to codfw (bacula2001, first disk array)Databases: Stored locally on the eqiad backup1001 second array of disks, it holds backups for codfw metadata and misc databases logical dumps. Pending to be renamed to DatabasesEqiad.DatabasesCodfw: equivalent to Databases, except in the reverse direction. It stores on Codfw (backup2001, second disk array) metadata and misc database backups generated on eqiad.EsRoEqiad: External Store (wiki content) Read-only Database backups at eqiad, it stores es1-3 backups (long term, 5 years) from codfw into backup1002EsRwEqiad: External Store (wiki content) Read-write Database backups at eqiad, it stores es4-5 backups (regularly scheduled) from codfw into backup1002EsRoCodfw: External Store (wiki content) Read-only Database backups at codfw, it stores es1-3 backups (long term, 5 years) from eqiad into backup2002EsRwCodfw: External Store (wiki content) Read-write Database backups at codfw, it stores es4-5 backups (regularly scheduled) from eqiad into backup2002
Architecture update (2020, 2022)

After a hw renewal, work started on improving architecture of all backups. This was kickstarted by the fact that offsite backups had an unreliable behavior, and that database backups were taken on both datacenters, and it would be a waste of resources to store them twice on each dc, given their size.
The general idea is at first only for Databases (maybe this could be extended to other kinds of backups), because backups are generated and stored short term on dbprov* hosts, general usage (provisioning of new or reimaged hosts) or the most common disaster recovery doesn't normally require bacula (which stores them for longer term). However, we still want to use bacula to keep them longer than just a couple of weeks, just in case (1-3 months).

On the other side, we generate backups independently on each dc to avoid things like "data corruption affecting all backups" in a dc, so we would want to preserve both copies, just not twice.
The solution proposed is to generate backups on each dc, keep them for a short period of time, and then send them to the other dc's bacula storage (in a crossing way, as the picture shows) for increased redundancy. If a full DC becomes unavailable, or data from a source completely corrupted, we still have the short-term backups locally, and the long term backups of the other dc (one of the two is likely to be useful, and with more probability, the short-term local ones). The disadvantage is that bacula runs will be less efficiently/slowly (happening over the WAN) and that if one wants recovery of older backups of a specific DC, it will also take more to recover.
We would have redundant directors and metadata databases in an active-active fashion so that the loss of a storage node or an entire dc node would have no impact on backups availability, and immediately we would have a way to recover data without having to (re)setup anything.
Configuration management
Everything must be done via Puppet. There is a puppet module for this and role classes for director and storage daemon.
Adding a new client
In the director (if needed)
Edit modules/profile/manifests/backup/filesets.pp profile and add:
bacula::director::fileset { 'myfileset':
includes = [ '/srv/important_dir',
'/srv/another_important_file.json',
],
}
If the path is a common one ('/', '/srv', ...) it may be already there because another server is backing up the same fileset. You can create a separate fileset with the same content but different name if you believe that it may change in the future. However, if servers with identical or equivalent roles require the same kind of backups, please use the same fileset so they are modified at the same time (filesets are just logical identifiers for paths/list of paths, use your best judgement when reusing them). You can also create multiple jobs for the same host if it makes sense to be logically separate, and/or they need separate backup policies (e.g. a server with 2 profiles).
The myfileset variable should be noted though because it will be used below. myfileset should not contain forward or backward slashes. Keep it short, but meaningful.
In the client
- Add
profile::backup::hostprofile to the host's role (this will enable, but not activate backups) - Add
backup::set { 'myfileset': }to the relevant profile of the host
Backup Strategy
Two autocreated volume, autolabeled file-backed pools storing all levels in the first one (production). An archival one for historical purposes exists as well.
The following 4 types of backup schedules are standarized for WMF servers:
- Monthly: Fulls monthly, diffs every other fortnight, incr. daily (this is the default)
- Hourly: Full weekly, incremental hourly
- Weekly: Only fulls, weekly
- Daily: Only fulls, daily
They are scheduled at different days of the week to distribute the load.
Operations
Handy cheatsheet: https://workaround.org/bacula-cheatsheet
Monitoring
- Please note that backup alerts do not page, as they are rarely time-sensitive, however, that doesn't mean they should not be taken seriously, specially if ongoing for some time.
On director/storage systems there is an alert that checks each daemon is up and running. This is just a basic check that prevents from keeping merged a bad or non-configuration, as well as other kind of host-related fatal error. This should be a relatively rare event, if it happens you should check:
- Check journalctl/syslog to understand the state of the daemon
- Try to start it and monitor the above logs to get an error message
- Check previously merged changes to backup profile or bacula module
- Check general host state of the host, including its disk arrays
The more interesting check is the bacula freshness alert, present only on the director. This will be green if and only if it finds at least 1 full and one incremental or differential backup with the configured freshness (with some extra buffer to be lenient for normal delays) for each puppet configured job. For example, if one has configured a backup of MyHost as "Monthly on Thursdays", it should generate an incremental or differential each week, and a Monthly Full backup. The check will be green only of it find a correct full backup in the last 32 days, and the latest backup of any kind in the last 8 days. The alert will summarize the global status by classifying backups in the following way, for easier triaging (from better to worse):
- Fresh: Latest backups were successful (defined as they terminated successfully, and as an additional condition for full, they are non-0 byte backups)
- No backups: there were no backups or attempts to backing up recorded (successful or not). This could be just a new, recently configured to be backed up host, or something weird happening with the scheduling/configuration
- Stale-full only: there are backups, but the full are stale (meaning older than the expected date). This could mean that the latest full backup failed, or it is taking more than usual, or something is wrong with new generated backups
- Stale: there are backups (including at least a full one), but they are all older than expected, both the full and incrementals/differentials
- All failures: All backup attempts for this host failed, as long as there is a record
At the moment, the backup schedule is assumed from the name of the job, with the following hardcoded time thresholds to complete the backups:
- Hourly-*: Full weekly, incremental hourly; +1 day, +3 hours of buffer. Used for Gerrit.
- Daily-*: Full every day, no incrementals; +1 day of buffer. Used for GitLab dumps.
- Weekly-*: Only fulls, weekly; + 1 day of buffer. Used for database dumps.
- Monthly-*: (default): Fulls monthly, diffs every other fortnite, incr. daily; +1 day, +1 day of buffer. Used by most backup jobs.
How to proceed on alert will depend on the particular case:

check_bacula.py --icinga is the code ran by the icinga check. It will shorten the output, providing the hostname of the alphabetically first failure occurrence for easier debugging.
For a more verbose output of all jobs that failed or were successful, run it without parameters:
check_bacula.py
Please note that several independent jobs (one per configure fileset) can be configured on the same host. One can manually check the alert original data by running:
check_bacula.py <name_of_the_job>
(substitute by the appropriate job name), which is just a wrapper of running on the backup director shell: echo 'llist jobname=grafana1002.eqiad.wmnet-Monthly-1st-Fri-production-var-lib-grafana' | bconsole.
To get a list of configured jobs, you can run:
check_bacula.py --list-jobs

check_bacula.py --prometheus is also the command used by the prometheus exporter service to return metrics for the grafana dashboard: https://grafana.wikimedia.org/d/413r2vbWk/bacula For example, this are the stats of the gerrit job.
To understand the origin of the error, the bacula log, present at /var/lib/bacula/log will be very helpful on identifying if there was a recent attempt of backing up the specific host, and what were the causes of the error. Typical cases include:
- Breakage of the director (has it been down or misconfigured? Are director, client and storages the right version [FD < (DIR == SD)]?)
- Breakage of the storage daemon (are the RAIDs healthy?)
- Problem at the client (has the client been down for a long time? Is the port open and available?)
- Network connectivity issues between client and director/storage
- Has the backup set gone and/or is misconfigured?
Monitoring of storage/pools/volumes/devices: TBD
Ignore list
Sometimes, hosts with configured backups can be down for a long time, or backups be incorrectly configured for services that shouldn't really have them. While service owners should take care of handling this, sometimes it may be impractical of very difficult. There is an ignore list configured at puppet://modules/profile/files/backup/job_monitoring_ignorelist of configured jobs whose metrics are ignored and not sent to prometheus nor taken into account for the icinga alerts.
Day to day
Generally nothing. Occasionally we 've seen the following problem: The size of the backups would increase enough to throw the schedule out of plan, which means no immediately writeable volumes are around getting all backups paused while waiting for a volume to be allowed to be recycled. Judging whether this is a one time incident or a change in the schedule is required is a bit difficult, it requires knowing history a bit. In any case, the issue can be fix temporarily by purging the oldest volume around.
echo list media | sudo bconsole
should return the list of volumes, find the older one (LastWritten is your friend) and purge it
echo "purge volume=productionXXXX" | sudo bconsole
and backups should resume.
Statistics
To be created
Restore (aka Panic mode)
ssh to the current backup director machine (backup1001) and:
sudo bconsole- restore
- select from the menu the desired case (Most often 5: Most recent backup for a client)
- Select the server
- Choose the FileSet to be restored (unless there is only one, in that case it gets auto-selected)
- Use the new prompt to browse the list of files to be potentially recovered - the BVFS (bacula virtual filesystem). Standard ls, cd commands apply. mark the files/dirs you want restored.
- use the mark command to mark files you want to be restored. wildcards work, there is also unmark
- enter done
- modify the job if needed (for example change the destination directory)
- wait :-) (you can use the status director or messages command to see the status of the restore job)
- fetch your backups from /var/tmp/bacula-restores (on the client)
Troubleshooting common issues
Things that could go wrong:
- There are ongoing backups jobs that are blocking the execution of the restore. Only a limited amount of jobs can be run concurrently per storage location. This should no longer happen, as restores should have the highest job priority. If for some reason the restore is not starting right away and it is blocked on a non-time-sensitive backup job, kill the running backup:
status directorto check ongoing processes (pending, running, completed). A blocked job will show as: "is waiting for higher priority jobs to finish" "is waiting on max Storage jobs". Lower priority means more urgent. Backups are run with 10 priority and restores with 1.stop jobid=$JOBIDto pause an ongoing backup (this used to be buggy in the past) $JOBID is the numeric identifier of the job, on input commas are not used (just the integer, e.g.:437309)cancel jobid=$JOBIDas a last resort to kill and make an ongoing backup job fail
- if file metadata has been expired from the database because they were too old, you will not be able to browse the virtual file system and you will have to restore the entire fileset.
- Recovering older backups other than the latest is, of course, possible. There are several ways to do this- one can run check_bacula.py on the linux command line to get a list of configured backups, and
check_bacula.py <job-name>to get a list of available backups. The job ids can be used on the "restore by job id option" (3: Enter list of comma separated JobIds to select).
Restore from a non-existent host (missing private key)
If you try to restore from a host that has already been decommissioned you can still select it as a source for restore but you will have to select a different host as the target. Doing that you will see on the target host that the file structure will be restored but all files are empty.
On bconsole, using the "messages" command you can see what the issue was and you would expect a message "Error: Missing private key required to decrypt encrypted backup data.".
Luckily, Bacula encrypts all files with 2 keys, the host key and a global master key, which also happens to be the Puppet CA public key. You can see this in the /etc/bacula/bacula-fd.conf on any host as PKI Master Key = "/var/lib/puppet/ssl/certs/ca.pem".
To restore files in this case:
- On the Bacula director (eg. backup1001), make sure the client configuration exists (even if the client host itself is unavailable). If it was removed from puppet:
- disable puppet on the director host
- duplicate an existing client config in
/etc/bacula/clients.dand modify the name/host of the client to match the job to be restored - run
chown root:bacula $filename - reload the bacula-dir daemon.
- ssh to the puppetmaster (e.g. puppetmaster1001.eqiad.wmnet) and:
- cd to /var/lib/puppet/server/ssl/
- concatenate the Puppet CA key and CA cert: cat ca/ca_key.pem ca/ca_crt.pem and copy the result into your clipboard
- If older backups are required, those will be encrypted with the old certs, found at
puppetmaster:/srv/private/modules/secret/secrets/ssl/wmf_ca_20XX_20XX
| The important new bits |
|---|
|
- go back to the Bacula director (e.g. backup1001) and follow the normal restore steps above
- Cleanup: When the restore job finishes, on the host you are restoring to:
- check
/var/tmp/bacula-restores/(or other location you specified for restore) and verify files are not empty (non-0 size) - restore the original key:
sudo cp /etc/bacula/ssl/server-keypair.pem.bak /etc/bacula/ssl/server-keypair.pem && rm /etc/bacula/ssl/server-keypair.pem.bak(or just remove the new file if you used a separate path) - enable puppet again and force an agent run
sudo enable-puppet "recovery using the puppet key" - Make sure puppet is active again:
sudo run-puppet-agent, and the original key is reloaded automatically (otherwise you can run manuallysudo systemctl restart bacula-fd)
- check
- If you created a configuration for a non-existent host on the director host (eg. backup1001), then on the backup director:
- enable puppet again and run puppet
sudo -i puppet agent -tto ensure that it removed your additional config file from/etc/bacula/clients.d. systemctl reload bacula-diragain, and make sure it is running
- enable puppet again and run puppet
Modify a pool's retention (or other similar properties)
- Modify the puppet code necessary to update the pool definition config file. For example: https://gerrit.wikimedia.org/r/c/operations/puppet/+/554485/2/modules/profile/manifests/backup/director.pp (Merged as 9695ec8 )
- Deploy the puppet change on the puppet master, as usual
- Run puppet so it updates the file on the director, as well as refresh the director daemon
- run
bconsoleand reload the pool properties with theupdatecommand:
$ bconsole
Connecting to Director backup1001.eqiad.wmnet:9101
1000 OK: 103 backup1001.eqiad.wmnet Version: 9.4.2 (04 February 2019)
Enter a period to cancel a command.
*update
Automatically selected Catalog: production
Using Catalog "production"
Update choice:
1: Volume parameters
2: Pool from resource
3: Slots from autochanger
4: Long term statistics
5: Snapshot parameters
Choose catalog item to update (1-5): 2
The defined Pool resources are:
1: Archive
2: Databases
3: Default
4: offsite
5: production
Select Pool resource (1-5): 2
+--------+-----------+---------+---------+---------+------------+-----------------+--------------+ ...
| PoolId | Name | NumVols | MaxVols | UseOnce | UseCatalog | AcceptAnyVolume | VolRetention | ...
+--------+-----------+---------+---------+---------+------------+-----------------+--------------+ ...
| 5 | Databases | 5 | 60 | 0 | 1 | 0 | 7,776,000 | ...
+--------+-----------+---------+---------+---------+------------+-----------------+--------------+ ...
Pool DB record updated from resource.
You have messages.
You can check the update was successful listing the pools with the command list pools. Retention time is in seconds.
Bare metal recovery
There is a paid plugin by bacula system to allow baremetal recovery. However doing it manually is also relatively easy. It is quite straightforward as a procedure. It is roughly described below
- Boot with your Rescue Live CDROM.
- Start the Network.
- Re-partition your hard disk(s) as it was before (we are going to be dumping them via sfdisk maybe?)
- Re-format your partitions
- Install bacula-fd
- Perform a Bacula restore of all your files
- Re-install your boot loader
- Reboot