
Ganeti
Ganeti is a clustered virtual machine management software tool built on top of existing virtualization technologies such as Xen or KVM and other open source software. It supports both KVM and Xen. At WMF we only have KVM as an enabled hypervisor. Primary Ganeti web page is https://ganeti.org/.
At WMF, ganeti is used as a cluster management tool for production-network VPSes with services that help us run our clusters. After an evaluation process of Openstack vs Ganeti, Ganeti was chosen as a more fitting software for the job at hand.
Architecture Overview
Ganeti is architected as a shared nothing virtualization cluster with job management. There is one master node (per-site) that receives all jobs to be executed (create a VM, delete a VM, stop/start VMs, etc). The master node can be swapped between a preconfigured number of master candidates in case of a hardware failure. This avoids a single point of failure for cluster management operations.
For VM storage we use the DRBD backend. This provides "RAID-1 over the network" block devices which ensure that in the event of failure of a single hardware node, VMs may be restarted with minimal disruption on their secondary (backup) node. This also provides the capability to migrate VMs between hardware nodes (e.g. for hardware maintenance) without requiring a centralized storage backend.
Within a cluster, there's the notion of a node group. That's practically a group of hardware nodes. Think of it as nothing more than a subcluster division. Operations are usually constrained within a node group and do not cross the boundaries unless specifically instructed to. In our deployment, node groups are aligned with the physical row location of the hardware inside the datacenter (where possible). This allows us to diversify VMs across physical row locations within a single site, taking advantage of the additional of fault tolerance this can provide. In caching pop locations there is a single, "default" node group.
There's an excellent series of blog posts by Rudolph Bott here which describe Ganeti further:
- https://blog.bott.im/introduction-to-ganeti/
- https://blog.bott.im/bootstrapping-a-ganeti-cluster/
- https://blog.bott.im/ganeti-hardware-considerations/
- https://blog.bott.im/using-hooks-to-integrate-ganeti-with-external-tools/
A high level overview of the architecture is here https://docs.ganeti.org/docs/ganeti/2.14/html/_images/graphviz-246e5775f608681df9f62dbbe0a5d4120dc75f1c.png and more discussion about it is in https://docs.ganeti.org/docs/ganeti/2.14/html/design-2.0.html
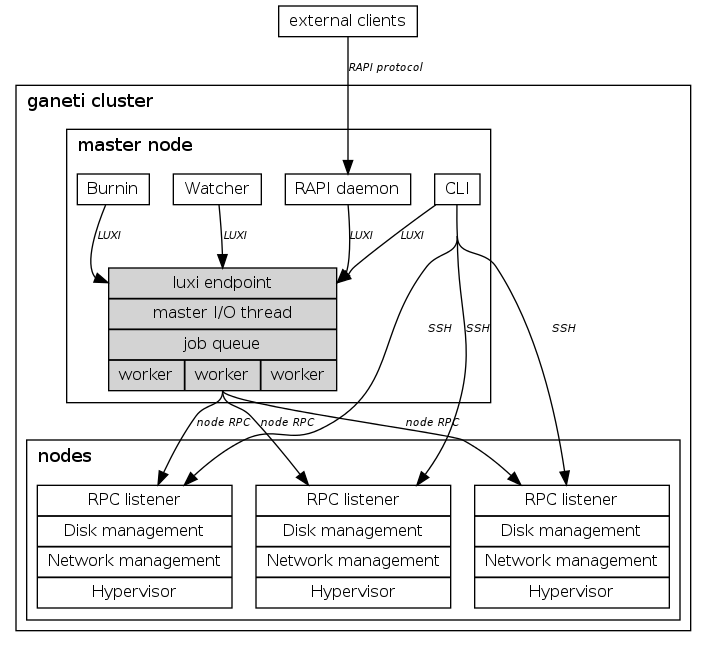{kind=link}
Ganeti Clusters
A cluster is identified by an FQDN (e.g ganeti01.svc.eqiad.wmnet) which corresponds to an IPv4 address. That IPv4 address is "floating", meaning that it is owned by the current master.
Administration always happens via the master. It is the only node where all commands can be run and hosts the API. Failover of a master is easy but manual. See below for more information on how to do it.
Hardware Conventions
As of Dec 2019 we have standardized on raid-5 host configuration in eqiad/codfw and an SSD backed raid-1 configuration in caching pop sites.
Connect to an existing cluster
Most operations are run from the Ganeti master node, but you can log into any of the virtualisation nodes via standard SSH. The MOTD of each Ganeti server will print the Ganeti master for the cluster.
Building a new cluster
Host Preparation
Node should be in the insetup role
New nodes should be initially installed with the puppet role insetup. At a later point in this procedure, after several manual actions, they'll be switched to the real ganeti role.
Ensure hardware virtualization is enabled in BIOS
Hardware virtualization must be enabled for KVM with the initial provision cookbook. If /dev/kvm is not present, the provision cookbook needs to be re-run.
Ensure 'ganeti' Volume Group is present
Our current ganeti partman layout creates a large raid device and formats it as swap to work around a shortcoming in the debian installer (fixme)
When a new ganeti host is built, you must manually remove the large swap device on /dev/md2, create a PV on /dev/md2, and create a VG called ‘ganeti’.
swapoff /dev/md2
pvcreate -y /dev/md2
vgcreate ganeti /dev/md2
Be sure to remove the stale swap entries from /etc/fstab.
Ensure network bridge(s) are present
(skip for routed Ganeti)
Bridges are used to connect virtual machines to the network interface of the hardware node. Currently these are manually configured. Each bridge corresponds to a network VLAN, on either a physical or tagged interface.
Make sure to install bridge-utils. It's a dependency of Ganeti, but not installed by default, so if you're setting up the bridge before the role gets applied, bridge-utils isn't installed and networking.service will fail with a cryptic/misleading error message.
Looking at the simpler case of the caching pop deployment, there is a single bridge called ‘private’ that corresponds with private network interface. This bridge interface assumes the IP of the node.
Example configuration:
#/etc/network/interfaces
# The loopback network interface
auto lo private
iface lo inet loopback
iface ens3f0np0 inet manual
iface private inet static
bridge_ports ens3f0np0
bridge_stp off
bridge_maxwait 0
bridge_fd 0
address 10.20.0.31/24
gateway 10.20.0.1
dns-nameservers 10.3.0.1
dns-search ulsfo.wmnet
up /sbin/ip token set ::10:20:0:31 dev private
up ip addr add 2620:0:862:102:10:20:0:31/64 dev private
## The original network interface configuration
#allow-hotplug ens3f0np0
#iface ens3f0np0 inet static
# address 10.20.0.31/24
# gateway 10.20.0.1
# dns-nameservers 10.3.0.1
# dns-search esams.wmnet
# pre-up /sbin/ip token set ::10:20:0:31 dev ens3f0np0
# up ip addr add 2620:0:862:102:10:20:0:31/64 dev ens3f0np0
Before editing the interfaces file, it's important to disable the puppet agent and leave it disabled until the role switch in a later step. If the agent re-runs the insetup role after the changes above, it will modify the file in a way that breaks networking.
After editing the interfaces file, a systemctl restart networking.services is required in order to take effect.
Generate an RAPI certificate for the cluster
The TLS certificates for the Ganeti RAPI endpoint are internally managed using the discovery endpoint of our PKI, no further setup steps are needed.
Create a SVC record for new cluster
The SVC record is used for the floating IP owned by a Ganeti master of a cluster. You need to create a new record following https://wikitech.wikimedia.org/wiki/DNS/Netbox#How_to_manually_allocate_a_special_purpose_IP_address_in_Netbox
After that the sre.dns.netbox cookbook needs to be run.
Assign the Ganeti Puppet role
Assign the ganeti Puppet role to the servers for regular L2 cluster.
Routed Ganeti
Assign the ganeti_routed Puppet role instead.
In Hiera set:
profile::ganeti::routed: true
profile::ganeti::tap_ip4:
public: XXX
private: YYY
Ensure intra-cluster SSH is permitted by the iptables/ferm firewall
Cluster nodes must be able to ssh to one another in order for Ganeti to function. Double-check that puppet has configured this by attempting to SSH between the Ganeti cluster hosts being deployed.
Initialize the new cluster
An example of a initializing a new cluster:
sudo gnt-cluster init \ --no-ssh-init \ --enabled-hypervisors=kvm \ --vg-name=ganeti \ --master-netdev=private \ --hypervisor-parameters kvm:kvm_path=/usr/bin/qemu-system-x86_64,kvm_flag=enabled,serial_speed=115200,migration_bandwidth=1000,migration_downtime=500,kernel_path= \ --nic-parameters=link=private \ ganeti01.svc.codfw.wmnet
The above is the way we currently have our clusters configured
For routed mode
- In Netbox, set the server's
BGPcustom fact totrue - Run Homer on the switch connected to the Ganeti server.
- Make sure BGP is established.
- Initialize the cluster with:
sudo gnt-cluster init --no-ssh-init --enabled-hypervisors=kvm --vg-name=ganeti --master-netdev=lo --hypervisor-parameters kvm:kvm_path=/usr/bin/qemu-system-x86_64,kvm_flag=enabled,serial_speed=115200,migration_bandwidth=64,migration_downtime=500,kernel_path= --nic-parameters=mode=routed,link=main ganeti02.svc.codfw.wmnet
(change the bold part)
Add the Ganeti group in Netbox
The Ganeti group needs to be created in https://netbox.wikimedia.org/virtualization/cluster-groups/ and associated with the VIP of the cluster.
In addition the new group needs to be added in hieradata/role/common/netbox/frontend.yaml.
With these changes, the Netbox sync should be working (started via systemd timers on the Netbox host)
Add nodes to new cluster (or extend an existing one)
Nodes can be added to the cluster using the sre.ganeti.addnode cookbook. It runs various consistency checks (whether virtualization is enabled in the BIOS, if the ganeti VG is present and if all the bridges (public/private and analytics in eqiad) are correctly set up) before making the change.
This cookbook requires the cluster's FQDN to be reachable.
Don't forget to also register the new node in Hiera (profile::ganeti::nodes), this variable gets read to setup the firewall rules.
Verify cluster health
Run `gnt-cluster verify` to perform a health check on the cluster. Address any errors that may occur before moving on.
Rename the Ganeti group
By default the Ganeti group is created as "default". You can run the following to use a more consistent name: (this name also needs to be be added to https://netbox.wikimedia.org/virtualization/clusters/)
sudo gnt-group rename default D
Ensure microcode flags are passed down to VM instances
In addition we need to adapt the QEMU settings so that new microcode flags are passed down to the instance:
sudo gnt-cluster modify -H kvm:cpu_type=IvyBridge\\,+pcid\\,+invpcid\\,+spec-ctrl\\,+ssbd\\,+md-clear
Configure a static KVM machine type
This makes future OS updates simpler:
sudo gnt-cluster modify --hypervisor-parameters kvm:machine_version=pc-i440fx-5.2
Create a test VM
The cluster should now be ready for VM creation, follow the 'create a VM' steps below and address any errors that may occur.
Modify an existing cluster
Modifying the cluster to change defaults, parameters of hypervisors, limits, security model etc is possible. An example of modifying the cluster is given below.
sudo gnt-cluster modify -H kvm:kvm_path=/usr/bin/qemu-system-x86_64,kvm_flag=enabled,kernel_path=
To get an idea of what is actually modifiable do a:
sudo gnt-cluster info
and then lookup in ganeti documentation the various options [1]
Destroy the cluster
Destroying the cluster is a one way street. Do not do it lightly. An example of destroying a cluster:
sudo gnt-cluster destroy --yes-do-it
do note that various things will be left behind. For example /var/lib/ganeti/queue/ will not be deleted. It's up to you if you want to delete it or not, depending on the case.
Listing cluster nodes
Listing all hardware nodes in a cluster:
sudo gnt-node list
That should return something like:
Node DTotal DFree MTotal MNode MFree Pinst Sinst ganeti1001.eqiad.wmnet 427.9G 427.9G 63.0G 391M 62.4G 0 0 ganeti1002.eqiad.wmnet 427.9G 427.9G 63.0G 289M 62.5G 0 0 ganeti1003.eqiad.wmnet 427.9G 427.9G 63.0G 288M 62.5G 0 0 ganeti1004.eqiad.wmnet 427.9G 427.9G 63.0G 288M 62.5G 0 0
The columns are respectively: Disk Total, Disk Free, Memory Total, Memory used by node itself, Memory Free, Instances for which this node is primary, instances for which this node is secondary
The nodegroup information you be obtained via a command like
sudo gnt-node list -o name,group
which would return the name and the group of node
Node Group ganeti1001.eqiad.wmnet C ganeti1002.eqiad.wmnet C ganeti1003.eqiad.wmnet C ganeti1004.eqiad.wmnet C ganeti1005.eqiad.wmnet A ganeti1006.eqiad.wmnet A ganeti1007.eqiad.wmnet A
To list all the hosts in a given group:
sudo gnt-instance list -o name -F "pnode.group == 'B'"
To check which row is underused and where you should put a new VM:
[ganeti1009:~] $ for row in A B C D; do echo "row ${row}: $(sudo gnt-instance list -o name -F "pnode.group == '${row}'" | wc -l) VMs"; done
Detecting the master node
The current master node of a cluster is printed in the MOTD when logging into a Ganeti server. It can also be detected with
sudo gnt-node list -o name,master_candidate,master
View the job queue
Ganeti has a job queue built-in. Most of the times it's working fine but if something is taking too long it might be helpful to check what's going on in the job queue
gnt-job list
and getting a job id from the result
gnt-job info #ID
Cluster upgrades
Hardware/software upgrades on a ganeti cluster can happen with 0 downtime to the VMs operations. The procedure to do so is outlined below. In case a shutdown/reboot is needed the procedure to empty to node is described in the rolling reboot section
Do the software upgrade (if needed)
apt upgrade, apt install <component>, debdeploy, whatever is the correct method
throughout the cluster. It should have 0 repercussions to any VM anyway. Barring a Ganeti bug in the upgraded version, the cluster itself should also have 0 problems. Between minor versions (e.g. 2.12 -> 2.15) it may be required to run some upgrade script. Read the changelog/upgrades notes. The Debian maintainer builds the package in a way that both versions will be installed and until you run said script the old version will still be used.
Rolling reboot
Doing a rolling reboot of the cluster is easy. Empty every node, reboot it, check that it is online, proceed to the next. The one thing to take care is to not reboot the master without failing it over first.
Failover the master
Choose a master candidate that suits you. You can get master candidates by
sudo gnt-node list -o name,master_candidate
Login and
sudo gnt-cluster master-failover
The cluster IP will now be served by the new node and the old one is no longer the master.
Cluster rebalancing
There might be a time where the cluster will look/actually be unbalanced. That will be true after a rolling reboot of the nodes. Doing a rebalancing is easy and baked into ganeti, all it takes is running a command
sudo hbal -L -X -G <node_group>
Please run it in a screen session. It might take quite a while to finish. The jobs have been submitted so it's fine losing that session but it's still prudent. A list of node groups can be displayed with "sudo gnt-group list".
The cluster will calculate a current score, run some heuristic algorithms to try and minimize that score and then execute the commands require to reach that state.
Cluster certificates
Ganeti creates and manages an internal Certificate Authority (CA). This CA is used for internal component communication and it's overall rather well hidden in day to day operations. There is a CA and node (aka client) certs that are distributed to the nodes. All nodes have the CA and the key to the CA, it's part of the ability to assume the master functionality. We 've decided to not mess with this CA as it is internal to the software and cluster state and we don't want to expose the key of the Puppet CA to the ganeti nodes.
The CA issues certs for the client nodes, the spice functionality (we don't use that) as well as the RAPI (remote API). Since we treat that CA as a blackbox, we don't want to use those. So in order to allow the rest of the infrastructure we run ganeti-rapid with the -K parameter and instead use a certificate we ship using Puppet. This can be confusing so keep an eye out.
Renew cluster certificates
The cluster certificates can be renewed at any point in time. While time consuming, it is a safe command to run (keep in mind that other operations will not be able to be run however during that timeframe). The command to do so is:
sudo gnt-cluster renew-crypto --new-cluster-certificate --new-node-certificates --new-rapi-certificate --new-spice-certificate --reason="<insert name> renewing crypto"
Note that we renew the cluster CA, the client certs, the spice certificate and the RAPI certificate. Don't be alarmed about renewing the RAPI certificate. As pointed out above, while the CA does issues one, we override the command to start ganeti-rapid and don't use the file that is created by the CA. So we can safely renew that too.
It will ask you to run gnt-cluster verify. Do so. If you see any errors, try to correct them and repeat.
Expired cluster certificates
So, you 've just met something like
Error checking node ganeti2004.codfw.wmnet: Error 60: server certificate verification failed. CAfile: /var/lib/ganeti/server.pem
What has happened is that the CA (and client certs) have expired. First, don't panic. While it must be fixed, it's not going to cause issues immediately. Relax and read through this section to understand what needs to be done.
Normally, we would just use the command in the section above to just renew everything but if we are this position we can't right away and need to perform a couple of more actions before that.
Prep work:
There's a couple of things that might interfere with you working. Those are puppet and ganeti cronjobs. Disable both before starting otherwise, you might end up scratching your head as race conditions might interfere with your work. To do so, run disable-puppet "<insert comment>" on all hosts via cumin and move /etc/cron.d/ganeti to some other place temporarily.
- Make sure you are on the master (if you used the ganeti01.svc.<site>.wmnet service url it should be already so).
- Write down the nodes participating in the cluster. Running the following should do it:
sudo gnt-node list
- Stop ganeti across the cluster. A cumin command 'systemctl stop ganeti' should do it. Don't worry, VMs will keep on running.
- Create a new CA. The easiest way to do so is:
chmod 0600 /var/lib/ganeti/server.pem && openssl req -new -newkey rsa:2048 -days 1825 -nodes -x509 -keyout /var/lib/ganeti/server.pem -out /var/lib/ganeti/server.pem -batch && chmod 0400 /var/lib/ganeti/server.pem
- Copy that cert to all hosts. Since the nodes have SSH allowed between them, you can just do that in a for loop
for i in ganetiX001.<site>.wmnet ganetiX002.<site>.wmnet ... ; do scp /var/lib/ganeti/server.pem $i:/var/lib/ganeti/server.pem ; ssh $i chmod 0400 /var/lib/ganeti/server.pem ; done
- Start ganeti across the cluster.
- Run a gnt-node list and note that this time the capacity of the hosts and usages are displayed normally and not with a question mark.
- Now run the gnt-cluster renew-crypto command from above.
- Follow the point about running gnt-cluster verify
- Correct errors if any and repeat.
- You are out of the woods.
Now re-enable puppet and move back /etc/cron.d/ganeti from wherever you placed it.
Routed Ganeti
Investigation and proof of concept blogpost: https://phabricator.wikimedia.org/phame/post/view/312/ganeti_on_modern_network_design/
Investigation and production grade deployment tracking task: https://phabricator.wikimedia.org/T300152
Currently routed clusters:
- (testing) codfw-AB - ganeti02.svc.codfw.wmnet - https://netbox.wikimedia.org/virtualization/clusters/112/
VM Operations
No changes from the existing workflows.
Cluster operations
See the "routed ganeti" sections in the general instructions above.
Differences with the regular VM provisioning
- Hypervisor side
- When creating the VM, spicerack adds extra variables passed on to Ganeti and Qemu (
opt/ip,opt/ip6) puppet:modules/profile/templates/ganeti/net-common.erbfunction setup_routeis executed each time a routed VM is started or migrated. Each VM is assigned a giventapXinterface.- Setup the static v4 and v6 routes to the VM's tap interface
- Setup an IP on the VM's tap interface
- Setup a static MAC on the VM's tap interface
- Enable routing on the VM's tap interface
- Disable proxy arp and inbound router advertisements on the VM's tap interface
- Start
isc-dhcp-relayon the VM's tap interface (and stops any existing one if any)
- The Bird BGP daemon constantly monitor for the above static routes, if present it re-advertises them to the top of rack switch
- When creating the VM, spicerack adds extra variables passed on to Ganeti and Qemu (
- VM side
puppet:modules/install_server/files/autoinstall/scripts/late_command.sh- Loads the Qemu firmware Kernel module from /target and retrieves the extra variables values passed by Spicerack (
opt/ip,opt/ip6) - Edit
/target/etc/network/interfacesto set the proper /128 IPv6 config
- Loads the Qemu firmware Kernel module from /target and retrieves the extra variables values passed by Spicerack (
- DHCP side
puppet:modules/install_server/templates/dhcp/dhcpd.conf.erb- In the subnet config stanza, sets
option subnet-mask 255.255.255.255(required) and removesoption broadcast-address(optional)
- In the subnet config stanza, sets
Limitations
- Only compatible with Debian Bookworm and up (debian-installer limitation with /32 IPs)
Notes
- Instructions on how to package
ipxe-qemuuntil it's updated in Debian on this task : https://phabricator.wikimedia.org/T369136
Future/possible improvements
- Remove hard-coded IPs from
puppet:modules/profile/manifests/ganeti.pp Add support for /32 IPs to iPXE - https://github.com/ipxe/ipxe/issues/1141- Done via sponsored work, waiting for the deb package to be updated in Debian - https://phabricator.wikimedia.org/T369136
Add support for /32 IPs to Debian Installer's netcfg - https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=1064005- Done via sponsored work, back-ported into Bookworm 12.6
Add support for public IPs VMs - https://phabricator.wikimedia.org/T362330- Add support for VM facing BGP to Bird - https://phabricator.wikimedia.org/T362392
- Feature request accepted from Bird maintainers
- Tighten up hypervisor ACLs (requires https://phabricator.wikimedia.org/T355042)
- Grow the cluster, start hosting production VMs
Fix Netbox PuppetDB import for /32 IPs : https://phabricator.wikimedia.org/T367265
Node operations
Reboot/Shutdown for maintenance a node
Select a node that needs rebooting/shutdown for brief hardware maintenance and empty of primary instances
sudo gnt-node migrate -f ganeti1004.eqiad.wmnet
Now a
sudo gnt-node list
should return 0 primary instances for the node. It is safe to reboot it or shut it down for a brief amount of time for hardware maintenance.
VMs without DRBD disk template
Note that there is a chance that this isn't true. We have a few instances that can't be migrated to other nodes. Those are things for which replicated storage (aka DRBD) is either an overkill (e.g. d-i-test) or a liability (e.g. etcd hosts where the extra IO latency by DRBD causes issues). For those VMs, which have the plain disk template, it's safe to just reboot the host, ganeti will DTRT.
After reboot, before you migrate the next node run
sudo gnt-cluster verify-disks
It should display "No disks need to be activated." (possibly multiple times, one per ganeti nodegroup) before the next node can be rebooted (this ensures that the DRBD is synced fully)
Shutdown a node for a prolonged period of time
Should the node be going down for an undetermined amount of time, also move the secondary instances
sudo gnt-node migrate -f <node_fqdn> sudo gnt-node evacuate -s <node_fqdn> # Removes it as a secondary as well
The second command means moving around DRBD pairs and syncing disk data. It is bound to take a long time, so find something else to do in the meanwhile
Now a
sudo gnt-node list
should return 0 for both primary instances as well as secondary instances. Before powering off the node we need to remove it from the cluster as well
sudo gnt-node remove <node_fqdn>
NOTE: Do not forget to readd it after it is fixed (if it ever is)
sudo gnt-node add <node_fqdn>
Failed hardware node
When a host is having problem (hardware/kernel/otherwise) and it's unreachable, the are a number of possible avenues to solve the issue, but an empirical good way out is:
- Just powercycle the host. If that works, it's probably the faster way out. Most services should anyway be set up highly available and if we got one that is not we either should set it that way or not care too much when it fails. If this works, you are done, if not keep on reading.
- If the above doesn't work (the node never comes back up), start the VMs on another host. This can be done with
sudo gnt-node failover -f <node_fqdn>
in some very rare cases you may have to ignore the consistency checks: pass --ignore-consistency. Again all important services are set in high available setups (and could easily reimaged) be so this will only severely bite VMs that are not setup that way.
- Remove the host from the cluster
sudo gnt-node remove <node_fqdn>
- Debug/fix/RMA the node.
VM operations
Listing VMs
sudo gnt-instance list
Create a VM
Most of the steps are the same as for production so keep in mind the regular process as well.
However, the reimage cookbook works only on physical host with an IPMI interface, so it cannot be used for VMs. So while the network boot installation will be unattended, VM creation is explained below, and Puppet signing and other steps is done with the manual procedure.
Verify cluster resource availability
First check how the Ganeti rows are currently used, to balance out resource allocation. We have a Ganeti cookbook for this:
$ sudo cookbook -d sre.ganeti.resource-report eqiad START - Cookbook sre.ganeti.resource-report +-------+-------+-----------+----------+-----------+---------+-----------+ | Group | Nodes | Instances | MFree | MFree avg | DFree | DFree avg | +-------+-------+-----------+----------+-----------+---------+-----------+ | A | 7 | 36 | 267.2GiB | 38.2GiB | 13.4TiB | 1.9TiB | | B | 6 | 33 | 209.8GiB | 35.0GiB | 9.8TiB | 1.6TiB | | C | 7 | 36 | 270.9GiB | 38.7GiB | 13.1TiB | 1.9TiB | | D | 6 | 34 | 230.3GiB | 38.4GiB | 10.6TiB | 1.8TiB | +-------+-------+-----------+----------+-----------+---------+-----------+ END (PASS) - Cookbook sre.ganeti.resource-report (exit_code=0)
If you want to confirm the reason why creating a VM fails is really due to lack of resources you can look at the ganeti command.log. For example in eqiad you would check the current master node ganeti1003:
[ganeti1003:~] $ sudo grep failure /var/log/ganeti/commands.log
OpPrereqError: ("Can't compute nodes using iallocator 'hail': Request failed: Group C (preferred): No valid allocation solutions, failure reasons: FailMem: 9, FailDisk: 3", 'insufficient_resources')
Assign a hostname
You need to select a hostname based on our Infrastructure_naming_conventions. You should also add Cumin aliases to cover selecting the new hostnames. See Cumin#Global_grammar_host_selection and edit modules/profile/templates/cumin/aliases.yaml.erb in operations/puppet. If you are making a new 'cluster', you'll also need to add a $cluster_$dc definitions to hieradata/common/monitoring.yaml.
The IP allocation and the generation of DNS records are handled automatically by Netbox.
Create partman config
The modules/profile/data/profile/installserver/preseed.yaml config file in the puppet repository contains partitioning information for servers. As of this writing, all Ganeti VMs should use ['partman/flat.cfg', 'virtual.cfg']. When adding a new instance you need to verify whether a partman config is assigned. If your host isn't covered by an existing entry, you'll need to add an entry to this configuration file.
After that you need to regenerate /srv/autoinstall/netboot.cfg on the apt* servers, by running Puppet:
sudo cumin 'C:install_server::preseed_server' 'run-puppet-agent'
Create the VM
Ganeti VMs are created with the sre.ganeti.makevm cookbook. You can use it from any Cumin host like the following:
$ sudo cookbook sre.ganeti.makevm -h
usage: cookbook [-h] [--skip-v6] [--vcpus VCPUS] [--memory MEMORY] [--disk DISK] [--network {public,private,analytics}] --os {stretch,buster,bullseye,bookworm,none} [-t TASK_ID] --cluster CLUSTER [--group GROUP] hostname
Create a new Virtual Machine in Ganeti
* Pre-allocate the primary IPs and set their DNS name
* Update the DNS records
* Create the VM on Ganeti
* Force a sync of Ganeti VMs to Netbox in the same DC
* Update Netbox attaching the pre-allocated IPs to the host's primary interface
Examples:
Create a Ganeti VM vmname.codfw.wmnet in the codfw Ganeti cluster
on group B with 1 vCPUs, 3GB of RAM, 100GB of disk in the private network:
makevm --vcpus 1 --memory 3 --disk 100 --cluster codfw --group B vmhostname
positional arguments:
hostname The hostname for the VM (not the FQDN).
optional arguments:
-h, --help show this help message and exit
--skip-v6 To skip the generation of the IPv6 DNS record. (default: False)
--vcpus VCPUS The number of virtual CPUs to assign to the VM. (default: 1)
--memory MEMORY The amount of RAM to allocate to the VM in GB. (default: 1)
--disk DISK The amount of disk to allocate to the VM in GB. (default: 10)
--network {public,private,analytics}
--os {stretch,buster,bullseye,bookworm,none}
the Debian version to install. One of stretch, buster, bullseye, bookworm, none, use "none" to skip installation (default: None)
-t TASK_ID, --task-id TASK_ID
Specify the type of network to assign to the VM. (default: private)
--cluster CLUSTER The Ganeti cluster short name, as reported in Netbox as a Cluster Group:
https://netbox.wikimedia.org/virtualization/cluster-groups/ (default: None)
--group GROUP The Ganeti group name, as reported in Netbox as a Cluster for the given group:
https://netbox.wikimedia.org/virtualization/clusters/ (default: None)
Please note that creating a new instance takes several minutes, most of the times due to the provisioning of the disk space. The makevm cookbook returns the output of the Ganeti command periodically, in order to get a regular feedback about the status of the VM creation.
Install the operating system
If a role have not yet been assigned, you can use the "insetup" role to bootstrap the VM. In Puppet, in "manifests/site.pp" assign the role as seen in this example:
node /^mynewwm.eqiad\.wmnet$/ {
role(insetup::infrastructure_foundation)
}
Available roles are:
- insetup::core_platform
- insetup::data_engineering
- insetup::data_persistence
- insetup::infrastructure_foundation
- insetup::machine_learning
- insetup::observability
- insetup::search_platform
- insetup::serviceops
- insetup::serviceops_collab
- insetup::traffic
- insetup::wmcs
Please pick the role that best reflect either your team or the team who is responsible for the future use of the VM.
The VM can now be installed, using the reimaging cookbook. Remember to add the --new parameter to the cookbook. Without this parameter the VM is expected to exist in PuppetDB and the cookbook will fail. Replace T123456 with the correct Phabricator ticket number.
sudo cookbook sre.hosts.reimage --os bullseye -t T123456 --new mynewvm
The cookbook will ensure that the operating system is installed and configure Puppet.
You can follow along in the install process by connecting to the console of the VM using:
sudo gnt-instance console <fqdn>
Ctrl+] to leave the console
Sync Hiera from Netbox
After at most 15 minutes the Ganeti VM metadata will be synced to Netbox from the Ganeti API. At that point run the sre.puppet.sync-netbox-hiera cookbook to export the metadata of the new VM to Hiera from Netbox.
Assign role to the VM in puppet
As usual. If the VM will not be installed immediately turn it off (see shutdown below). Running VMs that are not in Puppet will alarm.
Delete a VM
The preferred method is to run the decommissioning cookbook Decom_script that will take care of everything, including deleting the VM itself. See also the actions performed by the sre.hosts.decommission cookbook.
To instead irrevocably delete manually a VM run:
gnt-instance remove <fqdn>
In all cases please remember to clean up Puppet/DHCP/DNS entries afterwards.
Shutdown/startup a VM
gnt-instance startup <fqdn> gnt-instance shutdown <fqdn>
Note: In the shutdown command, ACPI will be used to achieve a graceful shutdown of the VM. A 2 minute timeout exists however, after which the VM will be forcefully shutdown. In case you prefer to not wait those 2 minutes, --timeout exists and can be used like so
gnt-instance shutdown --timeout 0 <fqdn>
Get a console for a VM
You can get log into the "console" for a Ganeti instance via
gnt-instance console <fqdn>
The console can be left with "ctrl + ]"
If the above fails then it is possible to use SPICE instead.
- Stop the VM
- Enable SPICE:
sudo gnt-instance modify -H spice_bind=127.0.0.1 <fqdn> - Get the listening port:
sudo gnt-instance info <fqdn> | grep 'Allocated network port' - Start the VM
- Set up port forwarding port over ssh (on your workstation):
ssh -L <spice_port>:localhost:<spice_port> <hypervisor_fqdn> - start your SPICE client:
remote-viewer spice://localhost:11010
Resize a VM
Increase/Decrease CPU/RAM
Make sure first that the cluster has adequate space for whatever resource you want to increase (if you do want to increase and not decrease a resource). This is done manually by a combination of grafana statistics for CPU/Memory utilization and the output of gnt-node list for disk space utilization. After that you can issue the following command to increase/decrease the memory size and number of Virtual CPUs assigned to a VM
gnt-instance modify -B memory=<X>[gm],vcpus=<N> <fqdn>
where X, N are physical numbers. X can be suffixed by g or m for Gigabytes or Megabytes (please don't do Terabytes ;))
After making the change, the VM needs to be restarted with the new setting:
sudo cookbook sre.ganeti.reboot-vm -r ... -t T... --depool <fqdn>
Adding disk space
Adding space to an existing disk is possible. But it is not advisable. Only do so sparingly and when you know it's the best course of action. A good example is if you know that the VM will be reimaged after the process. The reason is that growing a disk with a partition table in it means that the partition table will need to be updated as well (and after that the filesystem as well). This is a non automated process, error prone and requires at least 2 reboots (one for the VM to see the new disk size, and one for the VM to safely use the new partition table - that latter one can be avoided manually, but it's usually cheaper to just reboot the VM).
But do note that the resizing of partitions and filesystems is up to you, as ganeti can't do it for you. The command would be:
gnt-instance grow-disk <fqdn> <#> X[gmt]
where # is the index of the disk (it's 0 indexed). You can get the disks allocated to a VM using gnt-instance info <fqdn>. Again X is a physical number suffixed for Gigabytes/Megabytes/Terabytes.
Example:
# 1. Grow disk, may be done online $ sudo gnt-instance grow-disk --absolute mx2001.wikimedia.org 0 50g # 2. Poweroff $ sudo poweroff # 3. Start ganeti instance $ sudo gnt-instance start mx2001.wikimedia.org # 4. Resize the partition, if partition is not at the end of the disk, # other partitions may need to be removed $ sudo parted /dev/vda # 5. Resize the filesystem $ sudo resize2fs /
Adding a disk
Adding a disk is also easy if you want to avoid the mess that will result from having to resize partitions/filesystems. Thus it is recommended over resizing a disk. The command would be:
gnt-instance modify --disk add:size=X[gmt] <fqdn>
Again X is a physical number suffixed for Gigabytes/Megabytes/Terabytes.
WARNING!! After adding a device you have to reboot the VM (from ganeti level, not just reboot within the VM) and it might happen that your device names change and you get no networking.
If the VM does not come back from reboot, login via console and root password from pwstore and replace the device name with the "next" one in /etc/network/interfaces. For example replace all occurrences of "ens5" with "ens6" and reboot the machine one more time. also see phab:T272555. If you want to be sure about the "next" device name run ifconfig -a to double check.
After the disk has been created and the VM rebooted you need to create a partition table on it (fdisk), create a file system (mkfs.ext4) and mount it. Finally don't forget to add that to /etc/fstab to make sure it survives a reboot.
Hint: if you know beforehand that a VM will need an extra disk, add it before the install phase. In that case you only need to add the disk, and no other step.
Removing a disk
In case a VM no longer requires a disk, it can be removed. The command would be:
gnt-instance modify --disk <#>:remove <fqdn>
where # is the index of the disk (it's 0 indexed). You can get the disks allocated to a VM using gnt-instance info <fqdn>
Reinstall / Reimage a VM
Just like a physical server OS reinstall this will destroy the contents of the machine and requires appropriate netboot configs to be in place. Proceed with caution!
Reimaging a virtual host, running on Ganeti, is similar to reimaging a physical host, and uses the same cookbook:
sudo cookbook sre.hosts.reimage --os bullseye -t T12345 somevm1001
Renumber (aka change network) a VM
Say you want to change the networking configuration of a VM. It's usually better to create a new VM in the correct row instead. However there are some benefits to renumbering a VM like avoiding to have to re instantiate some database or some other lengthy to setup process. Some other indicative reasons for that would be:
- Spreading a cluster of VMs offering a service across more network rows.
- Rebalancing VMs across rows to free up capacity in a problematic row.
Steps are:
- Make sure the VM isn't powering some service (e.g. depool from pybal, if the VM is in a cluster, remove from the rest of the cluster's configuration)
- Choose a new row in the DC. Same rules are for creating a VM apply.
- Schedule downtime.
- Update DNS. Make sure you don't forget updating IPv6 :-)
- Update the networking configuration in /etc/network/interfaces. This is an error prone process with no review. Make sure you get it right otherwise you are in for some painful debugging
- Update the /etc/hosts referencing the host with the new IPv4 address
- If possible, power off the VM.
- Run the following command
sudo gnt-instance change-group --to=<row> <instance>
Wait it out.
Power on or reboot the VM
Set boot order
If you need to set a boot_order back to PXE to reinstall, it's "boot_order=network" (For KVM the boot order is either "floppy", "cdrom", "disk" or "network".
You can set the boot order manually, using the following command:
gnt-instance modify --hypervisor-parameters=boot_order=disk <fqdn>
Changing disk template for a VM (aka drop / disable DRBD)
In some specific cases it makes sense to disable DRBD disk replication to another Ganeti node. For example a replicated Redis, a replicated MySQL or a distributed datastore like cassandra, etcd, or zookeeper.
In some of the above cases, DRBD will not only be a waste but also cause issues. For example etcd, where the IO latency added by DRBD causes etcd to periodically complain about lag and syncing issues. This is usually seen via icinga alerts. The fix for this is to switch from DRBD to the plain template.
Note: If your rationale for disabling DRBD isn't already well established, stop here and talk the plan over with the maintainers of Ganeti and the owners of the service(s) to be deployed.
Automated steps
Run the sre.ganeti.changedisk cookbook to convert the disk template of a VM.
Usage example:
cookbook sre.ganeti.changedisk --cluster codfw --disktype plain --fqdn myserver2001.codfw.wmnet
Manual steps
Stop first the VM as the disk template change can't happen with the VM up
$ sudo gnt-instance shutdown foobar.eqiad.wmnet
With the VM stopped, change the disk template
$ sudo gnt-instance modify -t plain foobar.eqiad.wmnet Tue Feb 9 13:53:05 2021 Converting disk template from 'drbd' to 'plain' Tue Feb 9 13:53:05 2021 Removing volumes on the secondary node... Tue Feb 9 13:53:06 2021 Removing unneeded volumes on the primary node... Modified instance foobar.eqiad.wmnet - disk_template -> plain Please don't forget that most parameters take effect only at the next (re)start of the instance initiated by ganeti; restarting from within the instance will not be enough.
Start now the VM again
$ sudo gnt-instance startup foobar.eqiad.wmnet
Memory pressure
We have memory pressure icinga checks. Ganeti nodes are heavily memory bound and rather inflexible (that is, memory does not change a lot over time, once a VM is started it obtains that memory and uses it. We don't do ballooning, there is little gain in that currently). When a memory pressure icinga check happens, the best bet is to just rebalance the cluster or at least the nodegroup (representing a rack row currently). See Ganeti#Cluster rebalancing
Accessing the API
Ganeti offers a remote API, which comes in handy sometimes. Documentation is available at https://docs.ganeti.org/docs/ganeti/3.0/html/rapi.html#ganeti-remote-api
The API is readonly and needs a password. You need to access one of the SVC endpoints (specified per cluster with the profile::ganeti::rapi::certificate Hiera variable). The username is ro_user and the password can be found in the private repository under hieradata/common/profile/ganeti/rapi.yaml. An example:
curl --basic --user ro_user https://ganeti-test01.svc.codfw.wmnet:5080/2/instances
Manual recovery from partial install
In the case where cookbooks fail to install and configure a VM correctly, there is a number of manual step that can be taken in an attempt to recover the install.
Note: This assumes that the operating system has been installed, but subsequent steps are failing.
Ensure that the VM is not stuck in a boot loop, by setting the boot order to disk and reboot the VM:
$ gnt-instance modify --hypervisor-parameters=boot_order=disk <fqdn
$ gnt-instance startup <fqdn>
$ gnt-instance shutdown <fqdn>
Next login to one of the puppetmasters and run the following command (which will enable you obtain/access root shell of the targeted VM, identified by FQDN provided)
$ sudo install-console <FQDN>
You will be dropped into a root shell belonging to your newly created VM instance. On the VM root shell, initiate a puppet run by executing the following:
$ puppet agent -tv
The first Puppet run triggers a request for the certificate, it should show up when running "sudo puppet cert -l" on puppetmaster1001. Next approve the certificate with:
$ sudo puppet cert -s <FQDN>
Once the first puppet run has completed, the interface_automation/ImportPuppetDB Netbox script will be automatically run by the netbox_ganeti_$DC_sync timers that run on the Netbox hosts to to synchronize the VM interfaces to Netbox.
Notes
All of the commands that have a Y/N prompt can be forced with a -f. For example the following will spare you the prompt
gnt-instance remove -f <fqdn>
All commands are actually jobs. If you would rather not wait on the prompt --submit will do the trick
gnt-instance shutdown --submit <fqdn>
Netbox naming disambiguation
| Ganeti | Netbox | Example | Description |
|---|---|---|---|
| Cluster | Cluster Groups | codfw | Ensemble of Ganeti groups, share the mgmt plane |
| Group | Cluster | A (in codfw) | Ensemble of Ganeti nodes, share the data plane (can move VMs between nodes) |
| Node | Device | ganeti2001 | Physical server |