During the outage window, users connected to the primary (eqiad) datacenter may have had incomplete search results, messages saying "try your search again," and/or a lack of autocomplete.
Timeline
All times in UTC.
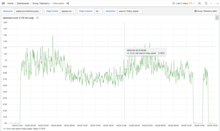
graph showing increased error rates for requests to the Elastic cluster2024-04-24 20:22 Search platform SREs merge this change and pool the new hosts, bringing elastic110[3-7] into the search cluster. Upstream error rate (as recorded from Envoy) begins to rise from < 0.1% to above 1%.
2024-04-25 03:13 Daily index update job for English Wikipedia fails at 44% due to connection problems from the maintenance host mwmaint1002 to the production eqiad Search cluster. Unfortunately, the incomplete index is promoted to production. Missing search results are reported by users in this Phab task.
2024-04-25 21:18 English Wikipedia index rebuild finishes successfully. Users now get a complete set of results, but error rate remains unacceptably high at ~1%.
2024-04-26 09:36 Dcausse (Search Platform SWE) points autocomplete Search traffic from the primary to secondary datacenter (codfw).
2024-04-26 13:31 At Dcausse's request, Akosiaris (SRE) depools the hosts that were pooled in step 1. Error rate drops back to normal, ending user impact. Ebernhardson, Dcausse and Bking (Search platform SWE/SRE) continue troubleshooting.
2024-04-26 16:34 Bking repools elastic1105 , which causes the error rate to shoot up again. Ebernhardon (Search Platform SWE) runs connectivity tests from mwmaint1002; they show a ~5% failure rate.
2024-04-26 16:55 Cmooney (SRE, Network SME) joins troubleshooting call. With his help, we're able to isolate the connection problems down to 2 hosts: elastic1105 and 1107. He identifies missing VLAN sub-interfaces on LVS load-balancer hosts and pushes a puppet patch to correct this.
2024-04-26 17:19 Cmooney completes push of changes to lvs1019 and validates that the required connectivity is now in place and working so elastic1105 and elastic1107 are reachable from it at L2.
2024-04-26 17:28 Bking repools elastic1103-1107 and confirms that no new errors have been logged. Ebernhardson and Bking decide to wait until Monday to repool Search autocomplete at the datacenter level.
2024-04-29 13:30 Switch autocomplete Search traffic back to eqiad
Detection
Write how the issue was first detected. Was automated monitoring first to detect it? Or a human reporting an error?
The problem turned out to be that two of the new hosts, elastic1105 and elastic1107, were in racks E5 and F5 in eqiad. That ought not to be a problem, but there had been an omission when provisioning the new vlans in these racks when they went live in early April. Specifically the new vlans assigned for the racks were not configured on our LVS load-balancers, which need to be on the same vlan as any backend server they have to send traffic to. The omission meant any time the new elastic hosts were selected by the load-balancer it tried and failed to connect to them, resulting in the errors. The fix was to add the configuration via puppet to create new vlan sub-interfaces on the LVS hosts so they had direct connectivity to new the racks/hosts.
Conclusions
What went well?
Part of the problem (incomplete search results) was detected and mitigated quickly.
What went poorly?
Detection took too long
Lack of monitoring
Bad healthcheck, or the architecture of Pybal cannot detect this type of connection failure.