
Incidents/2023-01-24 sessionstore quorum issues
document status: final
Summary
| Incident ID | 2023-01-24 sessionstore quorum issues | Start | 20:55 |
|---|---|---|---|
| Task | T327815 | End | 21:15 |
| People paged | 5 | Responder count | 6 |
| Coordinators | Brett Cornwall | Affected metrics/SLOs | No SLO exists. centrallogin and session loss metrics spiked as a result |
| Impact | Wikipedia's session storage suffered an outage of about 15 minutes (eqiad). This caused users to be unable to log in or edit pages. | ||
Session storage is provided by an HTTP service (Kask) that uses Cassandra for persistence. As part of routine maintenance, one of the Cassandra hosts in eqiad (sessionstore1001) was rebooted. While the host was down, connections were removed (de-pooled) by Kask, and requests rerouted to the remaining two, as expected. However, once the host rejoined the cluster, clients that selected sessionstore1001 as coordinator encountered errors (an inability to achieve LOCAL_QUORUM consistency).
This is likely (at least) similar to Incidents/2022-09-15 sessionstore quorum issues (if not in fact, the same issue).
Timeline
All times in UTC.
-
 Save failures due to "session loss"
Save failures due to "session loss" -
 Successful edits halving (one of two main DCs being affected)
Successful edits halving (one of two main DCs being affected) -
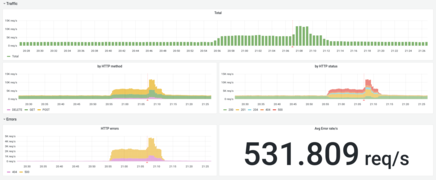 Overview of traffic
Overview of traffic



...
{"msg":"Error writing to storage (Cannot achieve consistency level LOCAL_QUORUM)","appname":"sessionstore","time":"2023-01-24T21:10:27Z","level":"ERROR","request_id":"ea9a0eef-256d-4eb1-bfd5-863a66aacee9"}
{"msg":"Error reading from storage (Cannot achieve consistency level LOCAL_QUORUM)","appname":"sessionstore","time":"2023-01-24T21:10:27Z","level":"ERROR","request_id":"58ad97ee-0025-4701-b288-4df39a38eb8a"}
...
...
INFO [StorageServiceShutdownHook] 2023-01-24 20:50:26,403 Server.java:179 - Stop listening for CQL clients
INFO [main] 2023-01-24 20:54:52,649 Server.java:159 - Starting listening for CQL clients on /10.64.0.144:9042 (encrypted)...
...
- 20:50 urandom reboots sessionstore1001.eqiad.wmnet (task T325132)
- 20:54 Cassandra on sessionstore1001 comes back online; Successful wiki edits drop to below half of expected number (OUTAGE BEGINS)
- 20:57 TheresNoTime notices drop in successful wiki edits, mentions in
#wikimedia-operations - 21:07 urandom rolling restarts sessionstore service (Kask)
- 21:09 Manual Critical page in VictorOps from
taavi - 21:10 Successful wiki edits climb back up to expected levels (OUTAGE ENDS)
- 21:14 De-pooling eqiad suggested but not yet executed
- 21:15 urandom notices cessation of issues, announces to
#wikimedia-operations
Detection
Monitoring did not alert; A manual page was issued once TheresNoTime noticed an issue/Users started reporting issues:
21:57:42 <TheresNoTime> Successful wiki edits has just started to drop, users reported repeated "loss of session data" persisting a refresh
As alerts did not fire, manual debugging was used to determine the issue at hand. It took little time to determine that SessionStorage was the issue.
Conclusions
What went well?
- Once the issue was identified, resolution was relatively quick
What went poorly?
- The dramatic detected session loss should have probably paged automatically
Where did we get lucky?
TheresNoTimewas able to catch the issue before any users/alerting systems alerted us.
Links to relevant documentation
- There is limited documentation on Kask debugging and behaviour.
Actionables
Setup notifications for elevated 500 error rate (sessionstore) (task T327960) Done
DoneNotifications from service error logs(?) (task T320401) DoneDetermine root cause of unavailable errors (i.e. "cannot achieve consistency level") (task T327954) DoneDe-pool datacenter prior to hosts reboots (as an interim to properly fixing the connection pooling) Done
Scorecard
| Question | Answer
(yes/no) |
Notes | |
|---|---|---|---|
| People | Were the people responding to this incident sufficiently different than the previous five incidents? | yes | |
| Were the people who responded prepared enough to respond effectively | no | Other people handled the issue. | |
| Were fewer than five people paged? | no | Alerts did not fire | |
| Were pages routed to the correct sub-team(s)? | no | Alerts did not fire | |
| Were pages routed to online (business hours) engineers? Answer “no” if engineers were paged after business hours. | no | Alerts did not fire | |
| Process | Was the "Incident status" section atop the Google Doc kept up-to-date during the incident? | no | There was no Google doc |
| Was a public wikimediastatus.net entry created? | yes | https://www.wikimediastatus.net/incidents/05cntb1k1myb | |
| Is there a phabricator task for the incident? | yes | phab:T327815 | |
| Are the documented action items assigned? | no | ||
| Is this incident sufficiently different from earlier incidents so as not to be a repeat occurrence? | no | Same failure mode but manifesting in a different way | |
| Tooling | To the best of your knowledge was the open task queue free of any tasks that would have prevented this incident? Answer “no” if there are open tasks that would prevent this incident or make mitigation easier if implemented. | no | There weren't open tasks as such, the failure mode was known and considered fixed |
| Were the people responding able to communicate effectively during the incident with the existing tooling? | yes | ||
| Did existing monitoring notify the initial responders? | no | ||
| Were the engineering tools that were to be used during the incident, available and in service? | yes | ||
| Were the steps taken to mitigate guided by an existing runbook? | no | ||
| Total score (count of all “yes” answers above) | 5 | ||